Google-API构建Web实时语音转文字情感分析
本教程中,我们将使用Google API中语音转文字以及自然语言分析功能,这是一个非常强大的人工智能平台,可以用来记录语音并将其转换为文本,并对文本进行实时情感分析。(Google API可能需要科学上网,但可以在文末选择国内的腾讯AI、百度AI平台进行替换)

首先罗列这个app的功能
- 创建Flask Web服务器
- 构建前端和后端
- 通过语音录入或者键盘输入的方式保存笔记
- 实时语音转文本
- 实时情绪识别
- 同时进行实时语音,文本,情感识别。
- 在任何云服务器上面上运行Angry-Ducks语音转文字情感分析助手
项目截图:
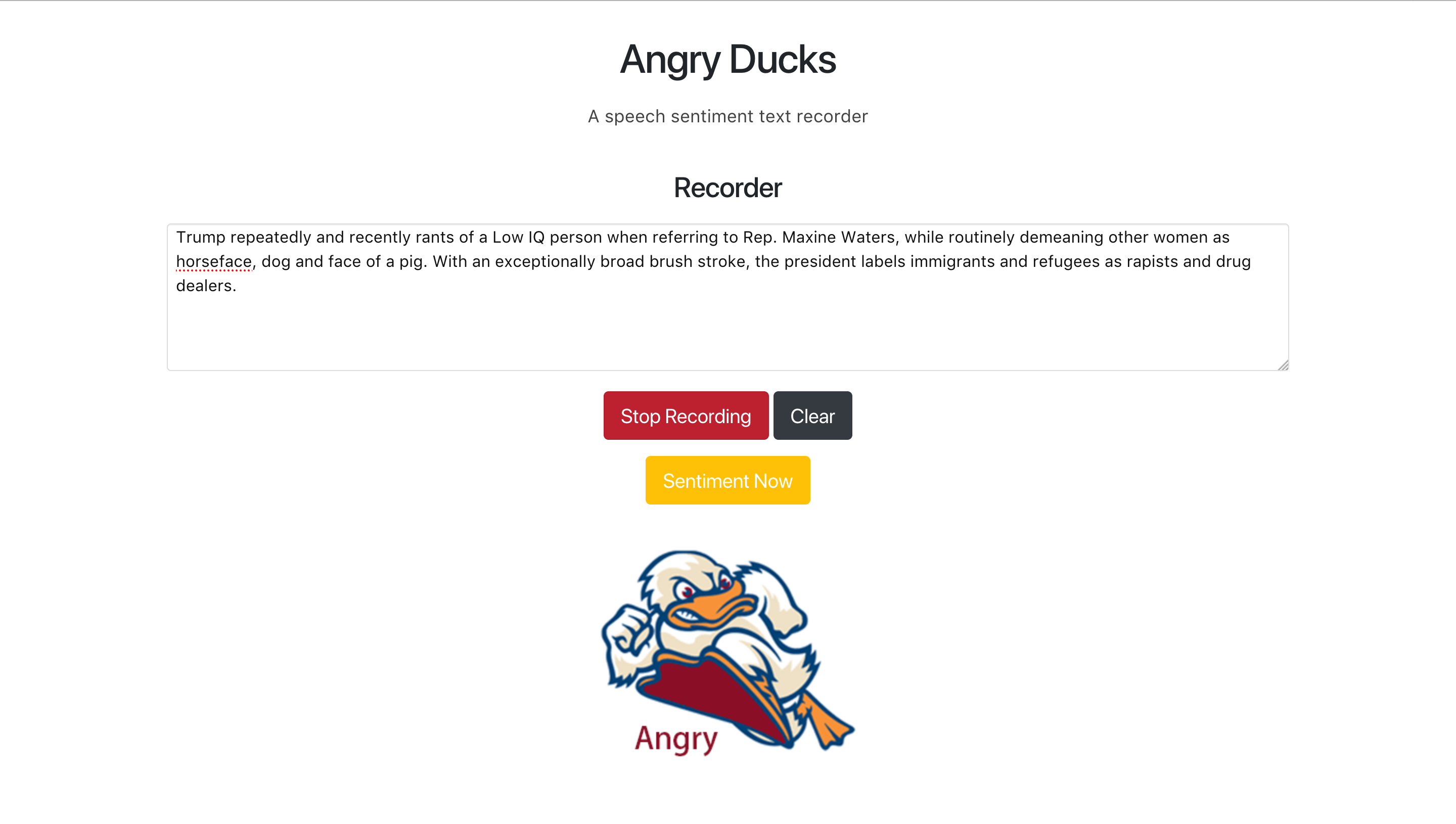
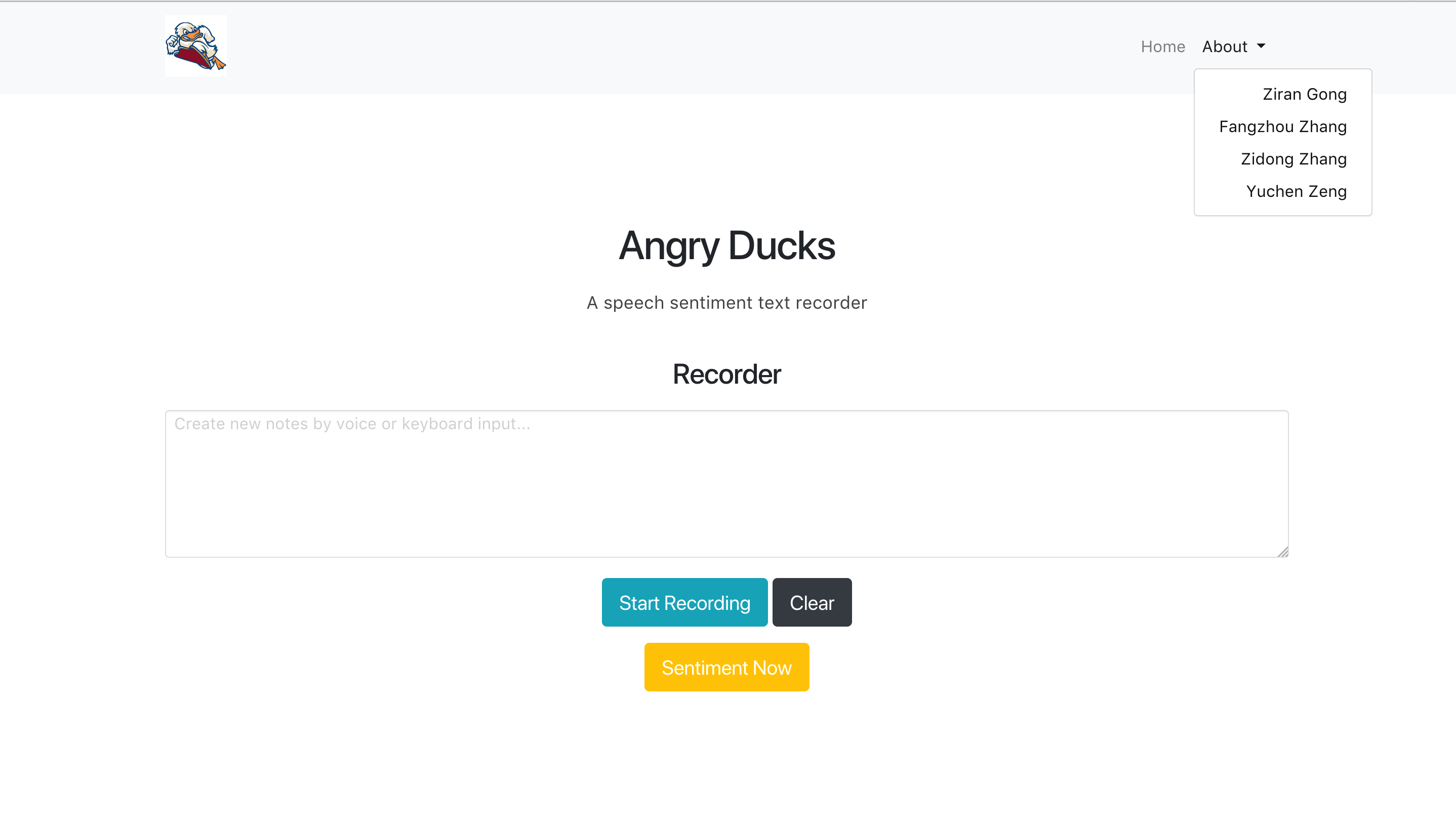
Google API语音转文本
下载gcloud工具并配置
- 准备工作
设置GCP控制台项目。
设置一个项目
创建或选择一个项目。
为该项目启用Speech-to-Text API。
创建服务帐户。
下载私钥作为JSON。
您可以随时在GCP控制台中查看和管理这些资源。
- 暗转和初始化Cloud SDK.
- 身份验证
对于身份验证,我们建议您使用服务帐号:即与您的 GCP 项目(而不是与特定用户)关联的 Google 帐号。无论代码在何处(本地、Compute Engine、App Engine 或内部等)运行,都可以使用服务帐号进行身份验证。如需详细了解其他身份验证类型,请参阅身份验证概览。
参考:https://cloud.google.com/docs/authentication/getting-started#auth-cloud-implicit-python
发出音频转录请求
现在您可以使用 Speech-to-Text 将音频文件转录为文字。使用以下代码示例向 Speech-to-Text API 发送 recognize 请求。
打开命令行 shell 并运行以下命令。
gcloud ml speech recognize 'gs://cloud-samples-tests/speech/brooklyn.flac' \
--language-code='en-US'
此命令请求 Speech-to-Text 转录一个 FLAC 中包含的音频,该 FLAC 在一个可公开访问的位置进行托管。
如果请求成功,服务器将返回 JSON 格式的响应:
{
"results": [
{
"alternatives": [
{
"confidence": 0.9840146,
"transcript": "how old is the Brooklyn Bridge"
}
]
}
]
}
恭喜!您已向 Cloud Speech-to-Text 发送了您的第一个请求!
Google API情感分析
点击链接开通即可
https://cloud.google.com/natural-language/?_ga=2.224506522.-145586126.1544583292
本项目语音转文本部分
Cloud Speech-to-Text 可实现将 Google 语音识别技术轻松集成到开发者应用中。向 Speech-to-Text API服务发送音频,即可收到文字转录结果。
注意: setting.py里面的GOOGLE_API = 'google-api.json'需要配置成自己的json文件,文件名可以修改
首先我们需要借助Recorder.js进行录音。建议使用Chrome和Firefox浏览器
然后通过aduck.js进行Recorder按钮的控制
$( document ).ready( function () {
var aduck = {};
aduck.init = function () {
aduck.createWebSocket();
aduck.initRecordButton();
aduck.initSentimentButtom();
};
aduck.getRecorder = function ( s ) {
context = new AudioContext();
source = context.createMediaStreamSource( s );
recorder = new Recorder( source, {
numChannels: 1,
} );
recorder.record();
aduck.setInterval();
};
aduck.createWebSocket = function () {
socket = io.connect( '//' + document.domain + ':' + location.port );
socket.on( 'connect', function () {
console.log( 'Connected!' );
} );
socket.on( 'transcript', function ( data ) {
console.log('data: ', data);
$( '.recognized-text' ).append( ' ' + data );
} );
};
aduck.setInterval = function () {
if ( 'undefined' !== typeof recorder ) {
exportInterval = setInterval( function () {
recorder.exportWAV( function ( blob ) {
recorder.clear();
if ( 'undefined' !== typeof socket ) {
console.log("blob: ", blob);
socket.emit( 'stream', blob );
}
} );
}, 5000 );
}
};
aduck.clearInterval = function () {
clearInterval( exportInterval );
};
aduck.initRecorder = function () {
if ( 'undefined' === typeof recorder ) {
navigator.mediaDevices.getUserMedia( {
audio: true,
video: false
} ).then( aduck.getRecorder );
}
};
aduck.initRecordButton = function () {
$( '.recorder' ).click( function ( e ) {
e.preventDefault();
if ( $( this ).hasClass( 'is-recording' ) ) { // Stop Recording
$( this ).removeClass( 'active is-recording btn-danger' ).text( 'Start Recording' );
if ( 'undefined' !== typeof recorder ) {
recorder.stop();
}
aduck.clearInterval();
}
else { // Start Recording
$( this ).addClass( 'active is-recording btn-danger' ).text( 'Stop Recording' );
if ( 'undefined' !== typeof recorder ) {
recorder.record();
aduck.setInterval();
}
else {
aduck.initRecorder();
}
}
} );
};
$( aduck.init() );
} );
后端通过processData函数进行语音转文字处理,并显示在前端界面:
app = Flask(__name__)
socketio = SocketIO(app)
# credentials, project = google.auth.default()
credentials = service_account.Credentials.from_service_account_file(
setting.GOOGLE_API)
credentials = credentials.with_scopes(
['https://www.googleapis.com/auth/cloud-platform'])
client = speech.SpeechClient(credentials=credentials)
def processData(data):
content = data
audio = types.RecognitionAudio(content=content)
config = types.RecognitionConfig(
encoding=enums.RecognitionConfig.AudioEncoding.LINEAR16,
language_code='en-US')
try:
response = client.recognize(config=config, audio=audio)
for result in response.results:
print('transcript: ', result.alternatives)
emit('transcript', result.alternatives[0].transcript)
except RetryError as e:
print("Error: {0}".format(e))
except:
print("Error:", sys.exc_info()[0])
一开始调用的时候浏览器将会弹出提示框,请求允许获得麦克风权限。
至此,语音转文本部分已经完成,下面我们继续实现文本情感。
实时文本情感
首先在aduck.js里面添加动态按钮,并对情感进行动态显示
aduck.initSentimentButtom = function(){
$( '.sentiment' ).click( function ( e ) {
e.preventDefault();
//log
console.log($(this))
var reconginized_text = $( '.recognized-text' ).val();
var xhr = new XMLHttpRequest();
//log
console.log( $( '.recognized-text' ).val());
// xhr.open("POST", '/sentiment?data=' + reconginized_text, true);
// xhr.send().then(function() {
// console.log('sentiment1: ', xhr.response);
// });
// console.log('sentiment: ', xhr.response)
const url = "/sentiment?data=" + reconginized_text;
fetch(url, {method: 'POST'})
.then( response => response.json())
.then( function(res) {
console.log(typeof res);
if (parseFloat(res.score) > 0.0) {
document.getElementById("duck-img").src="./static/images/happy.png";
// document.getElementById("angry-img").style.visibility="hidden";
// document.getElementById("neu-img").style.visibility="hidden";
} else if (parseFloat(res.score) < 0.0) {
document.getElementById("duck-img").src="./static/images/angry.png";
// document.getElementById("happy-img").style.visibility="hidden";
// document.getElementById("neu-img").style.visibility="hidden";
} else if (parseFloat(res.score) == 0.0) {
// document.getElementById("angry-img").style.visibility="hidden";
// document.getElementById("happy-img").style.visibility="hidden";
document.getElementById("duck-img").src="./static/images/neu.png";
}
});
});
};
实时文本情感分析detect_sentiment函数实现:
def detect_sentiment(text):
credentials = service_account.Credentials.from_service_account_file(
setting.GOOGLE_API)
credentials = credentials.with_scopes(
['https://www.googleapis.com/auth/cloud-platform'])
client = language.LanguageServiceClient(credentials=credentials)
document = types.Document(
content=text,
type=enums.Document.Type.PLAIN_TEXT)
# Detects the sentiment of the text
sentiment = client.analyze_sentiment(document=document).document_sentiment
print('Text: {}'.format(text))
print('Sentiment: {}, {}'.format(sentiment.score, sentiment.magnitude))
return sentiment
当此函数被调用时,会返回文本情感分析结果。
总结
在人工智能发展的今天,情感分析可以帮助我们对我们所说的话进行实时分析,协助我们对我们的情感进行判断。语音助手逐渐走进日常的生产和生活中。这样一个app可以帮助我们快速构建可以部署的Web人工智能服务。
完整项目地址:https://github.com/angryducks/angry-ducks
B站:https://www.bilibili.com/video/av44429125
Youtube: https://www.youtube.com/watch?v=lHrlYdO8gLY
如果你需要使用更多API实现更多的功能,可以试试下面的几个第三方API:
Face++人工智能开放平台
腾讯AI开放平台
百度AI开放平台
作者:
- nature1995 | 龚子然
- zfz | 张方舟
- zzdqqqq | 张子洞
- zlaomin | 曾宇晨
License
本软件根据GNU通用公共许可证v3.0许可证授权。 有关更多信息,请阅读该文件LICENSE.
请遵守开源协议,即便是在中国!!!